
Python for Finance Chapter1
Python for Finance Chapter1
I started to study the book of Python for Finance. With the previous foundation of python and the knowledge of financial numerical calculation, I think it should not be too difficult. Fighting! ! !
Part I. Python and Finance
This part introduces Python for finance. It consists of two chapters:
Chapter 1 discusses Python in general and argues in some detail why Python is well suited to addressing the technological challenges in the financial industry as well as in financial data analytics.
Chapter 2 is about Python infrastructure; it provides a concise overview of important aspects of managing a Python environment to get you started with interactive financial analytics and financial application development in Python.
Chapter 1. Why Python for Finance
Introduce Python balabala…
Python itself already comes with a large set of packages and modules that enhance the basic interpreter in different directions, known as the Python Standard Library. For example, basic mathematical calculations can be done without any importing, while more specialized mathematical functions need to be imported through the math module
1 | ln[1]:100 * 2.5 + 50 |
Without further imports, an error is raised.
After importing the
mathmodule, the calculation can be executed.
The Scientific Stack
There is a certain set of packages that is collectively labeled the scientific stack. This stack comprises, among others, the following packages:
NumPy provides a multidimensional array object to store homogeneous or heterogeneous data; it also provides optimized functions/methods to operate on this array object.
SciPy is a collection of subpackages and functions implementing important standard functionality often needed in science or finance; for example, one finds functions for cubic splines interpolation as well as for numerical integration.
This is the most popular plotting and visualization package for Python, providing both 2D and 3D visualization capabilities.
pandas builds on NumPy and provides richer classes for the management and analysis of time series and tabular data; it is tightly integrated with matplotlib for plotting and PyTables for data storage and retrieval.
scikit-learn is a popular machine learning (ML) package that provides a unified application programming interface (API) for many different ML algorithms, such as for estimation, classification, or clustering.
PyTables is a popular wrapper for the HDF5 data storage package; it is a package to implement optimized, disk-based I/O operations based on a hierarchical database/file format.
Technology in Finance
…
Python for Finance
Finance and Python Syntax
Most people who make their first steps with Python in a finance context may attack an algorithmic problem. This is similar to a scientist who, for example, wants to solve a differential equation, evaluate an integral, or simply visualize some data. In general, at this stage, little thought is given to topics like a formal development process, testing, documentation, or deployment. However, this especially seems to be the stage where people fall in love with Python. A major reason for this might be that Python syntax is generally quite close to the mathematical syntax used to describe scientific problems or financial algorithms.(我就是最近这样迷上python的)
This can be illustrated by a financial algorithm, namely the valuation of a European call option by Monte Carlo simulation.(一个蒙特卡罗计算欧式期权定价的例子)
- Initial stock index level S0 = 100 (股票初始价格)
- Strike price of the European call option K = 105 (期权的执行价格)
- Time to maturity T = 1 year (到期时间)
- Constant, riskless short rate r = 0.05 (固定的无风险利率)
- Constant volatility σσ = 0.2 (固定的波动率)
In the BSM model, the index level at maturity is a random variable given by BSM Equation below, with z being a standard normally distributed random variable.
Black-Scholes-Merton (1973) Equation:
$$
S_T = S_0exp((r-\frac{1}{2}\sigma^2)T+\sigma\sqrt{T}z))
$$
The following is an algorithmic description of the Monte Carlo valuation procedure:
- Draw I pseudo-random numbers $Z(i),i \in {1,2,\dots,I}$, from the standard normal distribution.
- Calculate all resulting index levels at maturity $S_T(i)$ for given $z(i)$ and Equation above.
- Calculate all inner values of the option at maturity as $h_T(i)=max(S_T(i)-k,0)$.
- Estimate the option present value via the Monte Carlo estimator as given in Equation blow.
Monte Carlo estimator for European option:
$$
C_0 \approx e^{-rT}\frac{1}{I}\sum_{I}h_T(i)
$$
This problem and algorithm must now be translated into Python. The following code implements the required steps:
1 | import math |
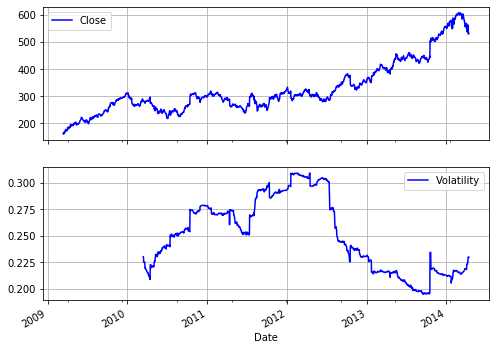
Consider a finance student who is writing their master’s thesis and is interested in S&P 500 index values. They want to analyze historical index levels for, say, a few years to see how the volatility of the index has fluctuated over time and hope to find evidence that volatility, in contrast to some typical model assumptions, fluctuates over time and is far from being constant. The results should also be visualized. The student mainly has to do the following:
- Retrieve index level data from the web
- Calculate the annualized rolling standard deviation of the log returns (volatility)
- Plot the index level data and the volatility results
1 | import numpy as np |
out:
| High | Low | Open | Close | Volume | Adj Close | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2014-04-08 | 553.480408 | 540.127075 | 541.114380 | 553.380676 | 3151200.0 | 553.380676 |
| 2014-04-09 | 563.822021 | 551.436035 | 558.087769 | 562.595398 | 3330800.0 | 562.595398 |
| 2014-04-10 | 563.453064 | 538.421753 | 563.453064 | 539.468872 | 4036800.0 | 539.468872 |
| 2014-04-11 | 538.521484 | 525.088379 | 531.091858 | 529.147217 | 3924800.0 | 529.147217 |
| 2014-04-14 | 542.610291 | 528.110046 | 536.776306 | 531.061951 | 2575000.0 | 531.061951 |
- Volatility
1 | goog['Log_Ret'] = np.log(goog['Close'] / goog['Close'].shift(1)) |
PERFORMANCE COMPUTING WITH PYTHON
1 | loops = 25000 |
14.4 ms ± 211 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
1 | import numpy as np |
377 µs ± 225 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Using NumPy considerably reduces the execution time to about 88 milliseconds. However, there is even a package specifically dedicated to this kind of task. It is called numexpr, for “numerical expressions.” It compiles the expression to improve upon the performance of the general NumPy functionality by, for example, avoiding in-memory copies of ndarray objects along the way:(使用 numexpr 库编译表达式,改善 numpy 的性能,例如在执行期间避免数组在内存中的复制)
1 | import numexpr as ne |
232 µs ± 201 ns per loop (mean ± std. dev. of 7 runs, 1000 loops each)
However, numexpr also has built-in capabilities to parallelize the execution of the respective operation. This allows us to use multiple threads of a CPU:(利用一个2核,4线程使用一个 GPU 的所有线程提高计算速度)
1 | ne.set_num_threads(4) |
122 µs ± 342 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
Python for Finance by Yves Hilpisch(O’Reilly).Copyright 2015 Yves Hilpisch,978-1-491-94528-5